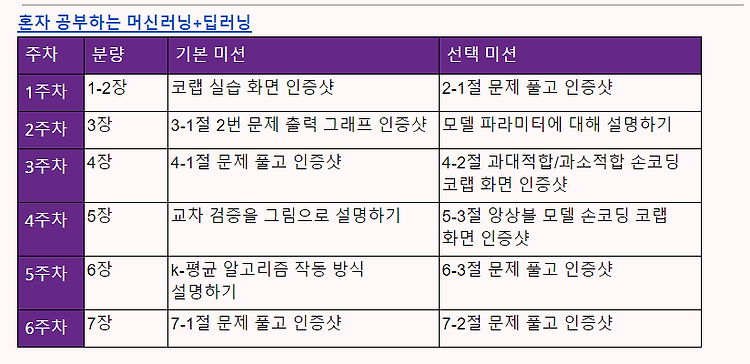
[이번주 과제 - 6주차] 1. 진도 공부 : 7장 딥러닝을 시작합니다 2. 기본 미션 : 7-1절 문제 풀고 인증샷 3. 선택 미션 : 7-2절 문제 풀고 인증샷 1. 진도 공부 1) 혼자 공부하는 머신러닝 + 딥러닝 7장 - 인공 신경망 링크 : sirokun.tistory.com/30 혼자 공부하는 머신러닝 + 딥러닝 7장 - 인공 신경망 1. 인공 신경망 - 생물학적 뉴런에서 영감을 받아 만든 머신러닝 알고리즘. - 기존의 머신러닝 알고리즘으로 다루기 힘들었던 이미지, 음성, 텍스트 분야에서 뛰어난 성능을 발휘하면서 주목받고 sirokun.tistory.com 2) 혼자 공부하는 머신러닝 + 딥러닝 7장 - 심층 신경망 링크 : sirokun.tistory.com/31 혼자 공부하는 머신러..