1. 손실 곡선과 검증 손실
- 에포크 횟수가 증가함에 따라 손실곡선이 어떻게 변화하는지 그래프로 그려보겠습니다.
#모델 생성
model = model_fn()
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=20, verbose=0,
validation_data=(val_scaled, val_target))
#손실곡선 그리기
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.savefig('7_3-04', dpi=300)
plt.show()

- 초기에 검증손실이 감소하지만 곧바로 다시 상승하는것을 볼수 있습니다. 하지만 훈련손실은 계속 감소하기 때문에 과대적합 모델이 만들어집니다.
<과대 적합을 막는 방법>
1) 옵티마이저 조정
- 옵티마이저를 조정하는 것으로 과대적합을 줄일 수도 있습니다. 보통 Adam을 사용할 경우 적응적 학습률을 사용하므로 학습률의 크기를 조정할 수 있습니다.
[Adam 적용실습코드]
#모델 생성
model = model_fn()
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=20, verbose=0,
validation_data=(val_scaled, val_target))
#손실곡선 그리기
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.savefig('7_3-05', dpi=300)
plt.show()
- 이전보다 더 뒤의 에포크에서 감소추세가 이어지는 것을 볼 수 있습니다.
2) 다양한 규제 방법 이용 : 드롭아웃, 콜백 등
- 다양한 규제 방법에 대한 설명은 아래에서 계속 설명하도록 하겠습니다.
2. 드롭아웃
- 훈련과정에서 층에 있는 일부 뉴런을 랜덤하게 꺼서 과대적합을 막는 방법
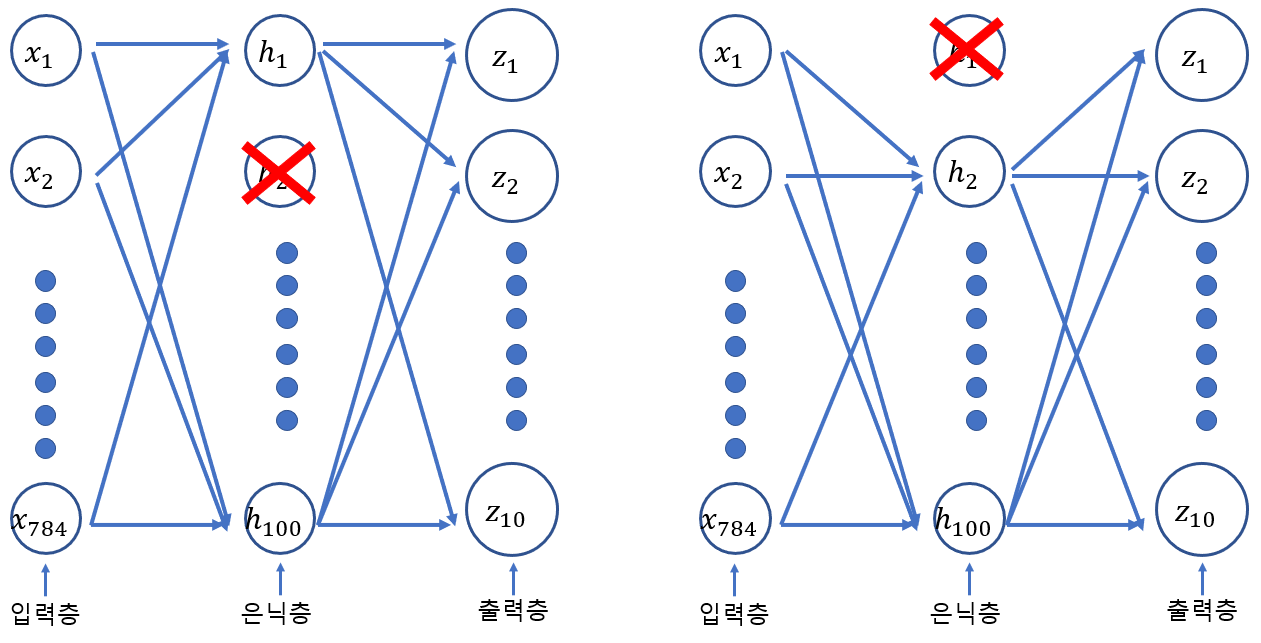
- 일부 뉴런이 랜덤하게 꺼지면 특정뉴런에 과대하게 의존하는 것을 주릴 수 있고 모든 입력에 주의를 기울여야 합니다. 일부 뉴런의 출력이 없을 수 있다는 것을 감안하면 이 신경망은 더 안정적인 예측을 만들 수 있을 것입니다.
- 또한 드롭아웃을 적용된 신경망을 보면 마치 앙상블을 하는 것과 동일해 보이는데, 그러므로 앙상블처럼 과대적합을 막는 효과도 기대해 볼수 있습니다.
[드롭아웃 적용실습코드]
#드롭아웃 층 추가
model = model_fn(keras.layers.Dropout(0.3))
model.summary()
#손실곡선 그리기
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=20, verbose=0,
validation_data=(val_scaled, val_target))
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.savefig('7_3-06', dpi=300)
plt.show()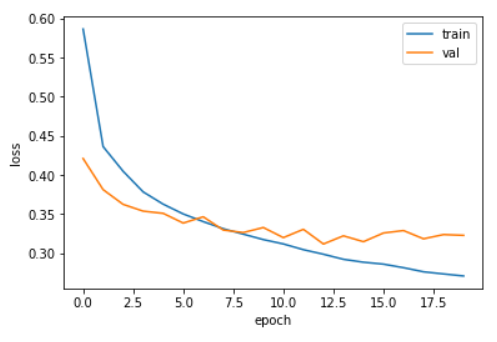
- 아까보다 확실히 과대적합이 줄어든 것을 확인할 수 있습니다.
3. 콜백
- 케라스 모델을 훈련하는 도중에 어떤 작업을 수행할 수 있도록 도와주는 도구
- 대표적으로 최상의 모델을 자동으로 저장해주거난 검증점수가 더 이상 향상되지 않으면 일찍 종료할 수 있습니다.
<조기종료>
- 검증 점수가 더 이상 감소하지 않고 상승하여 과대적합이 일어나면 훈련을 계속 진행하지 않고 멈추는 기법
- 조기종료를 사용하면 계산비용과 시간을 절약할 수 있습니다.
[콜백 & 조기종료 실습코드]
#모델 생성
model = model_fn(keras.layers.Dropout(0.3))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
# 최고모델 저장
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-model.h5')
# 조기종료 중단점 위치 저장
early_stopping_cb = keras.callbacks.EarlyStopping(patience=2,
restore_best_weights=True)
# 조기 종료 조건으로 모델 훈련
history = model.fit(train_scaled, train_target, epochs=20, verbose=0,
validation_data=(val_scaled, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])
#멈춘 에포크 위치 확인
print(early_stopping_cb.stopped_epoch)
>> 11
# 손실곡선 그리기
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.savefig('7_3-07', dpi=300)
plt.show()
+) 모델 저장과 복원
#모델 생성
model = model_fn(keras.layers.Dropout(0.3))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=10, verbose=0,
validation_data=(val_scaled, val_target))
#모델 파라미터 저장하기
model.save_weights('model-weights.h5')
#모델 저장하기
model.save('model-whole.h5')
#새로운 모델 생성
model = model_fn(keras.layers.Dropout(0.3))
#모델 파라미터 불러오기
model.load_weights('model-weights.h5')
#모델 불러오기
model = keras.models.load_model('model-whole.h5')
# 텐서플로 2.3에서는 버그(https://github.com/tensorflow/tensorflow/issues/42890) 때문에 compile() 메서드를 호출해야 합니다.
# model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
전체 실습 코드 : http://bit.ly/hg-07-3
'혼공단 > 혼공단 5기' 카테고리의 다른 글
| [혼공단 5기] 혼자 공부하는 머신러닝 + 딥러닝 6주차 후기 및 미션 인증 (+ 완주 소감) (0) | 2021.03.06 |
|---|---|
| 혼자 공부하는 머신러닝 + 딥러닝 7장 - 심층 신경망 (0) | 2021.03.05 |
| 혼자 공부하는 머신러닝 + 딥러닝 7장 - 인공 신경망 (0) | 2021.03.05 |
| [혼공단 5기] 혼자 공부하는 머신러닝 + 딥러닝 5주차 후기 및 미션 인증 (0) | 2021.02.28 |
| 혼자 공부하는 머신러닝 + 딥러닝 6장 - 주성분 분석 (0) | 2021.02.28 |