1. 심층 신경망
- 2개 이상의 층을 포함한 신경망.
- 다층 인공 신경망, 심층 신경망, 딥러닝을 같은 의미로 사용하기도 한다.
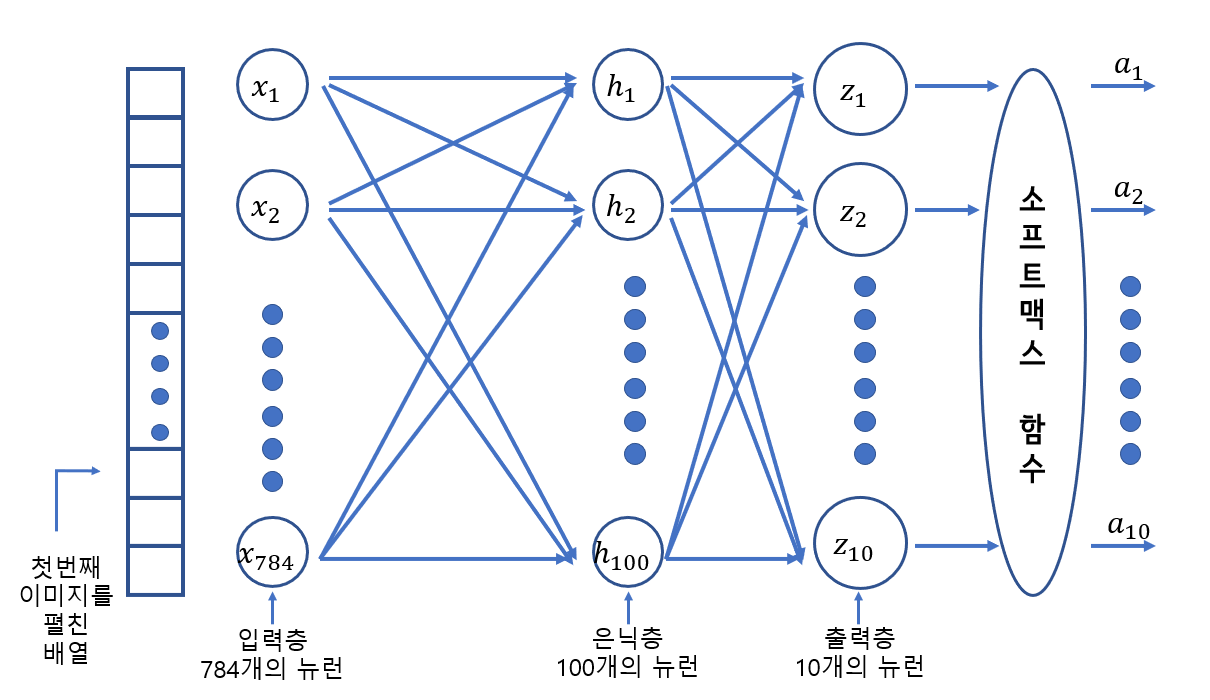
- 은닉층 : 입력층과 출력층 사이에 있는 모든 층
- 출력층에 적용하는 활성화 함수는 종류가 제한된다(이진 분류면 시그모이드, 다중 분류면 소프트맥스)
- 은닉층에 사용하는 활성화 함수는 비교적 자유롭다. (시그모이드, 볼 렐루 함수등이 사용됨)
2. 렐루 함수
- 이미지 분류 모델의 은닉층에 많이 사용하는 활성화 함수
- 층이 많을 수록 활성화 함수 양쪽 끝에서 변화가 작기 때문에 학습이 어려워지지만 렐루 함수는 이런문제가 없으며, 계산도 간단하다.

[실습코드]
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(100, activation='relu')) # 렐루 함수 적용
model.add(keras.layers.Dense(10, activation='softmax'))
3. 옵티마이저
- 신경망의 가중치와 절편을 학습하기 위한 알고리즘 또는 방법.
- 케라스에는 다양한 경사 하강법 알고리즘이 구현되어 있다.
<경사하강법 알고리즘 종류>

1) SGD
sgd = keras.optimizers.SGD()
model.compile(optimizer=sgd, loss='sparse_categorical_crossentropy', metrics='accuracy')- learining_rate로 학습률을 지정하며 기본값은 0.01
- 가장 기본적인 옵티마이저로 확률적 경사 하강법을 사용한다.
- 1개의 샘플을 뽑아서 훈련하지 않고 미니배치를 사용한다.
2) 모멘텀
sgd = keras.optimizers.SGD(momentum=0.9)- SGD클래스의 momentum 매개변수를 0보다 큰 값으로 지정하면 이전의 그레이디언트를 가속도 처럼 사용하는 모멘텀 최적화를 사용하게 된다. 보통 매개변수는 0.9이상을 지정한다.
3) 네스테로프 모멘텀
sgd = keras.optimizers.SGD(momentum=0.9, nesterov=True)- SGD 클래스의 nesterov 매개변수를 True로 바꾸면 네스테로프 모메텀 최적화를 사용한다.
- 모멘텀 최적화를 2번 반복하여 구현한다.
- 대부분의 경우 네스테로프 모멘텀 최적화가 기본 확률적 경사 하강법보다 더 나은 성능을 제공한다.
※ 모델이 최적점에 가까이 갈수록 학습률을 낮출 수 있다. 이렇게 하면 안정적으로 최적점에 수렴할 가능성이 높다. 이런 학습률을 적응적 학습률이라고 한다.
4) Adagrad
adagrad = keras.optimizers.Adagrad()
model.compile(optimizer=adagrad, loss='sparse_categorical_crossentropy', metrics='accuracy')- 적응적 학습률을 사용하는 대표적인 옵티마이저 중 하나.
- 그레이디언트 제곱을 누적하여 학습률을 나눈다.
- learining_rate로 학습률을 지정하며 기본값은 0.001
- initial_accumulator_value 매개변수에서 누적 초깃값을 지정할 수 있으며 기본값은 0.1이다.
5) RMSprop
rmsprop = keras.optimizers.RMSprop()
model.compile(optimizer=rmsprop, loss='sparse_categorical_crossentropy', metrics='accuracy')- 적응적 학습률을 사용하는 대표적인 옵티마이저 중 하나.
- Adagard처럼 그레이디언트 제곱으로 학습률을 나누지만 최근의 그레이디언트를 사용하기 위해 지수 감소를 사용한다.
- learining_rate로 학습률을 지정하며 기본값은 0.001
- rho 매개변수에서 감소 비율을 지정하며 기본값은 0.9
6) Adam
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')- 모멘텀 최적화와 RMSprop의 장점을 접목한 것이 Adam이다.
- keras.optimizers 패키지 아래에 있다.
- learining_rate로 학습률을 지정하며 기본값은 0.001
- beta_1으로 모멘텀 최적화에 있는 그레이디언트의 지수 감소 평균을 조절하며 기본값은 0.9
- beta_2으로 RMSprop에 있는 그레이디언트 제곱의 지수 감소 평균을 조절하며 기본값은 0.999
전체 실습 코드 : bit.ly/hg-07-2
'혼공단 > 혼공단 5기' 카테고리의 다른 글
| [혼공단 5기] 혼자 공부하는 머신러닝 + 딥러닝 6주차 후기 및 미션 인증 (+ 완주 소감) (0) | 2021.03.06 |
|---|---|
| 혼자 공부하는 머신러닝 + 딥러닝 7장 - 신경망 모델 훈련 (0) | 2021.03.06 |
| 혼자 공부하는 머신러닝 + 딥러닝 7장 - 인공 신경망 (0) | 2021.03.05 |
| [혼공단 5기] 혼자 공부하는 머신러닝 + 딥러닝 5주차 후기 및 미션 인증 (0) | 2021.02.28 |
| 혼자 공부하는 머신러닝 + 딥러닝 6장 - 주성분 분석 (0) | 2021.02.28 |