<진도표>
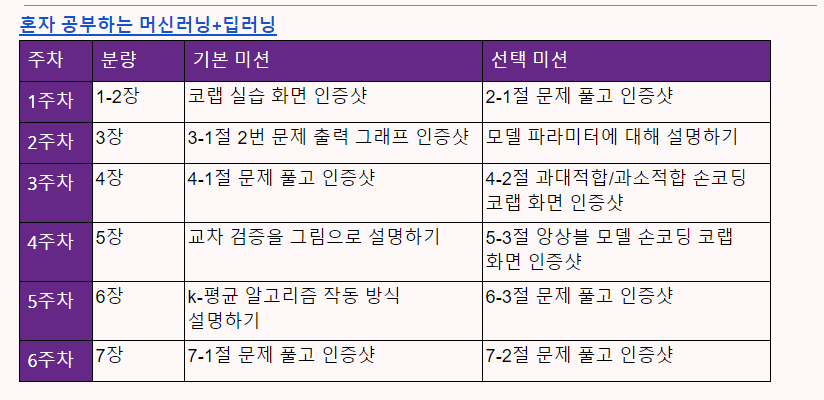
[이번주 과제 - 5주차]
1. 진도 공부 : 6장 비지도 학습
2. 기본 미션 : k-평균 알고리즘 작동 방식 설명하기
3. 선택 미션 : 6-3절 문제 풀고 인증샷
1. 진도 공부
1) 혼자 공부하는 머신러닝 + 딥러닝 6장 - 군집 알고리즘 & k-평균
혼자 공부하는 머신러닝 + 딥러닝 6장 - 군집 알고리즘 & k - 평균
1. 군집 <비지도 학습> - 머신러닝의 한 종류로 훈련 데이터에 타깃이 따로 없다. - 그러므로 스스로 유용한 무언가를 찾아 학습해야 한다. - 군집, 차원 축소등이 이에 해당한다. <군집> - 비슷한
sirokun.tistory.com
2) 혼자 공부 하는 머신러닝 + 딥러닝 6장 - 주성분 분석
혼자 공부하는 머신러닝 + 딥러닝 6장 - 주성분 분석
1. 차원과 차원 축소 차원 : 데이터가 가진 속성을 말한다. 특성과 동일한 의미이다 <차원 축소> - 비지도 학습 방법 중의 하나이다. - 데이터를 잘 나타내는 일부 특성을 선택하여 데이터 크기를
sirokun.tistory.com
이번주에는 비지도 학습에 대한 내용이 주를 이뤘습니다.
이때까지 지도학습만 배워왔기에 비지도학습은 새로운거라 더 어렵지 않을거라 생각했는데, 생각보다 쉬운 내용이어서 금방 이해할 수 있었습니다. 군집알고리즘과 주성분 분석 이렇게 크게 두가지 내용을 배웠는데, 맨 처음에 우리가 배웠던 k-최근접 이웃 알고리즘과 겹치는 내용이 많아서 이해하는게 수월했다고 생각합니다. 의외로 알고리즘이 비슷하게 겹치는게 많다고 느껴지기도 했고요.
2. 기본미션 : k-평균 알고리즘 작동 방식 설명하기
기본미션은 k-평균 알고리즘 작동 방식 설명하기입니다.
k-평균 알고리즘 작동 방식에 대한 설명은 진도 공부를 하면서 정리한 게시물에 적어놓기도 했습니다.
혼자 공부하는 머신러닝 + 딥러닝 6장 - 군집 알고리즘 & k - 평균
1. 군집 <비지도 학습> - 머신러닝의 한 종류로 훈련 데이터에 타깃이 따로 없다. - 그러므로 스스로 유용한 무언가를 찾아 학습해야 한다. - 군집, 차원 축소등이 이에 해당한다. <군집> - 비슷한
sirokun.tistory.com
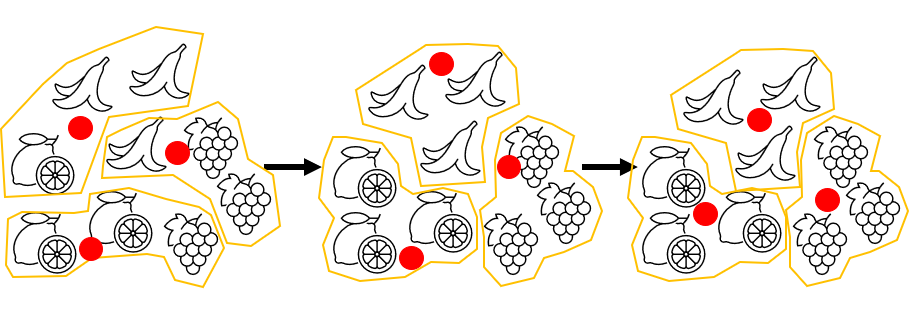
k-평균 알고리즘이란 처음에 랜덤하게 클러스터 중심을 정하고 클러스터를 만든다. 그 다음 클러스터의 중심을 이동하고, 다시 클러스터를 만드는 식으로 반복해서 최적의 클러스터를 구성하는 알고리즘입니다.
여기서 클러스터 중심은 k-평균 알고리즘이 만든 클러스터에 속한 샘플의 특성 평균값으로 센트로이드라고도 부릅니다.
3. 선택미션 : 6-3절 문제풀고 인증샷

선택미션은 6-3절 문제 풀고 인증샷입니다.
간단하게 풀이를 해보면 아래와 같습니다.
<1번 문제 풀이>
- 일반적으로 특성의 개수 만큼 주성분을 찾을 수 있습니다. 문제에선 특성이 20개이므로, 이 데이터 셋에서 찾을 수 있는 주성분의 개수는 2번 20개가 됩니다.
<2번 문제 풀이>
- (1000, 100) 크기 데이터셋에서 10개의 주성분을 찾아 변환하면 샘플의 개수는 바뀌지 않고, 특성의 개수만 100에서 10개로 바뀝니다. 따랏 정답은 1번 (1000,10)입니다.
<3번 문제 풀이>
- 주성분 분석은 가장 분산이 큰 방향부터 순서대로 찾습니다. 그렇기 때문에 분산이 가장 큰 주성분은 맨 첫번째 주성분이 되므로, 답은 1번이 됩니다.
이것으로 5주차 후기를 마쳐보겠습니다. 비지도 학습이란 생소한 분야로 혹여나 어렵지 않을까 싶었지만, 저번주보다는 쉬운 내용이라 더 빠르게 끝낼 수 있었던 것 같습니다.
벌써 다음주가 마지막 주차네요. 시작한게 엊그제 같은데, 벌써 마지막이라니...슬프기도 하면서, 마지막에 딥러닝으로 화려하게 끝이 나는 것 같기도 해서 기대반 걱정반입니다. 이제 알파고를 맛볼수 있는건가요?
'혼공단 > 혼공단 5기' 카테고리의 다른 글
| 혼자 공부하는 머신러닝 + 딥러닝 7장 - 심층 신경망 (0) | 2021.03.05 |
|---|---|
| 혼자 공부하는 머신러닝 + 딥러닝 7장 - 인공 신경망 (0) | 2021.03.05 |
| 혼자 공부하는 머신러닝 + 딥러닝 6장 - 주성분 분석 (0) | 2021.02.28 |
| 혼자 공부하는 머신러닝 + 딥러닝 6장 - 군집 알고리즘 & k - 평균 (0) | 2021.02.24 |
| [혼공단 5기] 혼자 공부하는 머신러닝 + 딥러닝 4주차 후기 및 미션 인증 (0) | 2021.02.19 |