04-1 데이터 수집하기
데이터 수집 : 분석할 데이터를 준비하는 과정
- 직접 데이터를 입력, 외부에서 생성한 데이터를 찾아서 불러오기, 서버에서 데이터를 호출하는 방법 등이 있다.
직접 데이터를 입력 : 벡터나 데이터프레임을 R에서 함수로 입력
외부데이터를 가져오기 : txt, csv, xlsx등의 파일을 가져오기
원시데이터 : 가공하지 않은 처음의 데이터, 원시 자료라고도 한다.
<직접 데이터 입력하기>
- 원시 데이터 입력은 c() 함수로 값을 변수에 할당한다.
변수명 <- c(값)- 벡터 만들기와 동일하다.
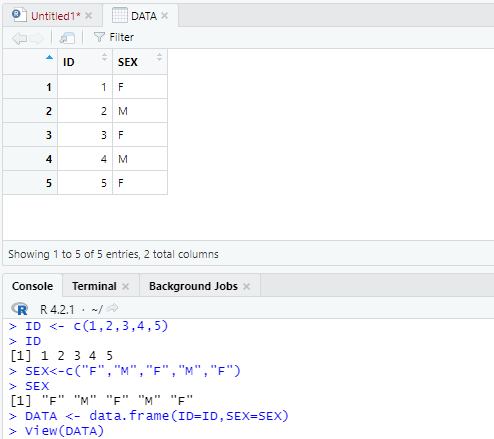
[View() 함수]
- 데이터 뷰어를 이용하면 데이터를 액셀처럼 정리된 상태로 볼수 있다.
- 또한 간단한 필터를 적용하거나 정렬을 실행할 수 있어 편리하다.
<외부 데이터 가져오기>
[TXT 파일]
- TXT 파일은 read.table()함수를 사용하여 데이터 프레임으로 가져올 수 있다.
read.table("원시 데이터",header=FALSE, skip = 0, nrows= -1, sep = "", ...)- 함수에 원시 데이터 파일 경로를 넣어주고, 필요하다면 옵션을 지정한다.
- header : 원시 데이터의 1행이 변수명인지 아닌지 판단, TRUE면 원시데이터 1행이 변수명임을 의미한다.
- skip : 특정 행까지 제외하고 데이터를 가져온다.
- nrows : 특정행까지의 데이터를 가져온다.
- sep : 데이터의 구분 문자를 지정한다.
- 만약 원시 데이터에 변수명으로 사용할 행이 없다면 col.names 옵션을 사용한다.
[CSV 파일]
- CSV 파일은 read.csv()함수를 사용하여 데이터 프레임으로 가져올 수 있다.
read.csv("원시 데이터")
[엑셀 파일]
- 엑셀 파일은 read.csv()함수를 사용하여 데이터 프레임으로 가져올 수 있다.
read_excel("원시 데이터")- read_excel()함수는 readxl패키지에 있는 함수이다. 고로 데이터를 가져오기 전에 먼저 readxl 패키지를 설치해야 한다.
[XML 파일]
- XML 파일 : HTML과 비슷하지만 데이터를 보여주는 것이 아닌 저장하고 전달하는 목적으로 만들어진 형식
- XML 파일은 가져오는 많은 방법들이 있지만, XML파일은 데이터 프레임으로 변환하는 xmlToDataFrame() 함수를 가장 많이 사용한다.
xmlToDataFrame("원시 데이터")- 이때 XML파일의 <>괄호안의 태그가 변수명으로 태그안의 값이 데이터 프레임에 저장이 된다.
- xmlToDataFrame() 함수는 XML 패키지에 있다. 함수를 사용하려면 XML패키지를 설치하고 로드해야 한다.
[JSON 파일]
- JSON 파일은 데이터 안에 다시 데이터가 정의된 중첩 데이터 구조로 이루어져 있다.
- JSON 파일을 가져오는 함수는 fromJSON() 함수이다.
fromJSON("원시 데이터")- fromJSON() 함수는 jsonlite패키지에 있다.
- fromJSON() 함수는 JSON파일을 데이터프레임이 아닌 리스트 형식으로 가져오게 된다.
04-2 데이터 관측하기
- View() 함수는 엑셀처럼 깔끔하게 볼 수 있지만 데이터가 방대하면 불러오는데 시간이 많이 걸린다.
- 그러므로 실제 데이터 분석에서는 데이터 요약 방법을 사용한다.
<내장 데이터 세트>
- data() 함수를 통해 내장 데이터 세트를 들고 올 수 있다.
data() : R에 내장된 데이터 세트 목록을 전부 확인
data("iris") : iris 데이터세트를 변수로 저장하여 가져온다.
<데이터 요약 확인하기>
[데이터 구조 확인하기]
- 데이터 구조는 str() 함수를 사용한다.

- 첫행에 150obs, of 5 variables의 의미는 5가지의 컬럼과 150개의 관측치를 가지고 있는 데이터 프레임이라는 의미이다.
- $는 컬럼명, num은 숫자형 데이터라는 의미이다,
- Species의 경우 Factor 자료형에 3가지 범주(w/3)로 구성되어 있다고 적혀있다.
[데이터 세트 컬럼 및 관측치 확인하기]
- ncol() 함수 : 데이터 프레임 컬럼(열)개수를 확인
ncol(변수명)- nrow() 함수 : 데이터 프레임 관측치(행)개수를 확인
nrow(변수명)- dim() 함수 :데이터 프레임 컬럼(열) 및 관측치(행) 개수를 확인
dim(변수명)
[데이터 세트 컬럼명 확인하기]
- ls() 함수 : 컬럼명을 확인할때 사용
ls(변수명)
[데이터 앞부분과 뒷부분값 확인하기]
- head() 함수나 tail()함수를 이용하면 데이터의 앞부분 혹은 뒷부분 값을 확인할 수 있다.
- 옵션 n을 이용해 개수를 변경할 수 있으며, 옵션을 설정하지 않으면 기본값으로 6개가 출력된다.
head(변수명, n = 수량)
tail(변수명, n = 수량)
<기술 통계량 확인하기>
- mean() 함수 : 평균을 구할때 사용
- median() 함수 : 중앙값을 구할때 사용
- min() 함수 : 최솟값을 구할때 사용
- max() 함수 : 최댓값을 구할때 사용
- range() 함수 : 범위를 구할때 사용(여기서 범위는 최댓값에서 최솟값의 범위를 의미)
- quantile() 함수 : 분위값을 구할때 사용, probs 옵션으로 1~3사분위의 값을 설정할 수 있다.
- var() 함수 : 분산을 구할때 사용, 분산이 작을수록 데이터는 평균에 몰려있다.
- sd() 함수 : 표준편차를 구할때 사용, 표준편차가 클수록 데이터는 넓게 퍼져있다.
[첨도와 왜도]
- 데이터의 비대칭도를 파악하는 기술 통계량
- 첨도와 왜도 함수를 사용하려면 psych 패키지가 필요하다.
1) 첨도
- 데이터 분포가 정규분포 대비 뾰족하 정도를 설명하는 통계량, 데이터가 어느정도로 중심에 몰려 있는지를 파악할 수 있다.
- kurtosi()함수로 구한다. 0보다 크면 뾰족한 것이고, 0보다 작으면 정규분포보다 완만하다는 의미이다.
2) 왜도
- 좌우 대칭여부를 판단
- skew()함수를 사용하며, 0에 가까울수록 좌우대칭이며 0보다 크면 오른쪽 꼬리를 가지고, 0보다 작으면 왼쪽 꼬리를 가진다.
[데이터 빈도 분석하기]
- 빈도분석 : 데이터의 항목별 빈도 및 빈도 비율을 나타내는 방법
- 빈도분석에는 freq() 함수를 사용한다.
freq(변수명)- freq() 함수는 descr 패키지에 포함되어 있다.
- freq() 함수의 plot = F 옵션은 막대 그래프 출력을 제외하는 옵션이다. 이 옵션없이 실행하면 막대그래프와 함께 실행된다.
04-3 데이터 탐색하기
[그래프]
- 데이터를 간결하고 쉽게 이해할 수 있도록 이미지화 또는 시각화한 것이 그래프
- 상자그림, 막대그래프, 히스토그램, 파이차트, 줄기 잎 그림, 산점도 등의 종류가 있다.
<막대 그래프 그리기>
1) freq() 함수
- freq()함수에 plot 옵션을 설정하면 막대그래프를 출력할 수 있다.
freq(변수명, plot = T, main = '그래프 제목')2) barplot() 함수
- barplot() 함수는 별도의 패키지를 설치하지 않아도 막대그래프를 그릴 수 있다.
- 하지만 빈도 분포를 구하는 기능이 없기때문에 table()함수를 함께 사용한다.
barplot(변수명. ylim=c(y축범위), main="그래프 제목",xlab="x축 제목", ylab="y축 제목",names=c("컬럼 제목",...),col=c("컬러",...),...)- ylim : 출력할 y축범위를 지정한다. c()함수를 사용해 벡터 형태로 지정한다.
- main : 그래프 제목을 지정한다.
- xlab : x축 제목을 지정한다.
- ylab : y축 제목을 지정한다.
- names : c() 함수를 사용해 벡터 형태로 컬럼 제목을 지정한다.
- col : c() 함수를 사용해 벡터 형태로 그래프 색상을 지정한다.
<상자 그림 그리기>
- 상자그림 : 데이터의 분포를 비교하거나 이상치를 판단할때 주로 사용하는 그래프
- 상자그림은 다음 그림과 같이 극단값(최댓값과 최솟값), 제3사분위수, 평균값, 중앙값, 제1사분위수의 5가지 항목을 시각화한 요약정보를 제공한다.

- 상자그림은 boxplot함수로 그린다.
boxplot(변수명. ylim=c(y축범위), main="그래프 제목",xlab="x축 제목", ylab="y축 제목",names=c("컬럼 제목",...),col=c("컬러",...),...)
- 옵션은 barplot과 동일하다.
<히스토그램 그리기>
- 히스토그램 : 연속형 데이털르 일정하게 나눈 구간(계급)을 가로축으로, 각 구간에 해당하는 데이터수(도수)를 세로축으로 그림 그래프
- 히스토그램을 이용하면 구간별 관측치 분포상태를 빠르게 확인할 수 있다.
- hist()함수를 통해 그린다.
hist(변수명. ylim=c(y축범위), main="그래프 제목",xlab="x축 제목", ylab="y축 제목",names=c("컬럼 제목",...),col=c("컬러",...),...)
[히스토그램과 막대그래프의 차이]
| 항목 | 히스토그램 | 막대 그래프 |
| 함수 | hist() | barplot() |
| 데이터 형태 | 연속형 | 이산형 |
| 데이터 예시 | 키,나이,금액 등 | 성별, 지역 등 |
| 그래프 형태 차이 | 그래프 막대가 붙어있음 | 그래프 막대가 분리된 경우가 많음 |
<파이차트 그리기>
- 파이차트 : 원을 데이터 범주 구성 비례에 따라 파이 조각을 나누는 것처럼 표현하는 그래프
- 여러꼴의 부채꼴 모양으로 구성된다.
- pie()함수로 출력하며, pie()함수에는 빈도 분석 기능이 없으므로 빈도분석을 하는 table() 함수를 실행한다.
<줄기 잎 그림 그리기>
- 줄기 잎 그림 : 변수 값을 자릿수로 분류하여 시각화하는 방법

- 줄기 잎 그림은 stem()함수를 사용하여 그린다.
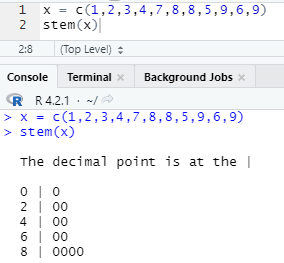
- The decimal point is at the | : 수직선을 기준으로 줄기는 일의 자리, 잎은 소수점이라는 의미
- 0| 구간은 1을 포함하고, 8| 구간은 9를 포함하게 된다.

- scale을 통해 구간을 조정할 수 있다. 기본값은 1이며 1보다 큰값을 할경우 그 배수만큼 늘어나며, 작게하면 그 값만큼 줄어든다.
<산점도 그리기>
- 산점도 : 두 변수간의 관계를 점으로 나타내 점들의 형태에 따라 산포도를 확인할 수 있으며, 산포도라고도 부른다.
- 산점도는 plot()함수를 사용하여 그린다. 이때 x,y값은 산점도 그래프 위치에 동그라미로 표시된다.
[산점도 행렬]
- 산점도들이 행렬로 나타나는것.
- 여러 변수들의 관계를 한번에 확인할 수 있는 그래프로 내장함수인 pairs() 함수로 그린다.
- 산점도 행렬은 psych패키지의 pairs.panel()함수로도 그릴수 있다. 사용방식은 pairs()와 동일하지만 psych 패키지를 설치해야 한다.
'혼공단 > 혼공단 8기' 카테고리의 다른 글
| 혼자 공부하는 R데이터분석 5장 - 데이터 가공하기 (0) | 2022.08.13 |
|---|---|
| [혼공단 8기] 혼자 공부하는 R 데이터 분석 4주차 후기 및 미션 인증하기 (0) | 2022.07.29 |
| [혼공단 8기] 혼자 공부하는 R 데이터 분석 3주차 후기 및 미션 인증하기 (0) | 2022.07.24 |
| 혼자 공부하는 R데이터분석 3장 - R프로그래밍 익히기 (0) | 2022.07.24 |
| [혼공단 8기] 혼자 공부하는 R 데이터 분석 2주차 후기 및 미션 인증하기 (0) | 2022.07.16 |